CNN is the most powerful neural network in computer vision.
Many application dealing with images can be used with CNN.
- Image classification
- Object detection
- Neural style transfer
What make the CNN different from neural network in computer vision?
Let’s see the reasons.
This post is based on the video lecture1 and Stanford article2
Why convolution?
In the previous posts, we know how to train the neural network with $X$ and $y$.
What if $X$ is image?
Assuming that we want to find the edge of box. It is hard to find with normal neural network. Because parameters will be trained the position of box on training samples. Also, The feature is getting larger depending on the size of images.
Let’s see CNN that is one of powerful models in image classification. The idea of CNN comes from how brain works when we see an image.
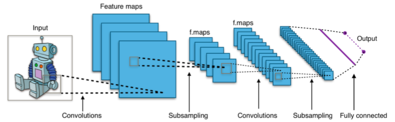
The type of layer in convolutional neural network
- convolution(conv)
- pooling(pool)
- Fully connected(FC)
The benefit of Convolution
Parameter sharing
A feature detector that’s useful in one part of the image is probably useful in another part of the image.
Sparsity of connection
In each layer, each output values depends only on a small number of inputs.
Convolution
In the image, how can you find edges?
With Neural network, the feature will too big to get the proper parameters without overfitting.
When you see an image to find edges, you will scan the top left side to bottom right of the image.
This idea is similar to convolution.
- $X$ is $6 \times 6$ image.
- $f$ is $3 \times 3$ filter.
- $\hat X$ is $4 \times 4$
The equation to get the result of convolution. \((n \times n ) * (f \times f) = (n-f+1) \times (n-f+1)\)
disadvantages
- Shrinking output
- Throw away information from edge
Most of deep learning libraries have options for padding.
- valid: no padding
- same: padding to make the size of result same with input
Strided convolution
How the filter is stepping \((n \times n ) * (f \times f) = (n-f+1) \times (n-f+1)\)
With 3D
Think like Lego block. The bigger block can be build by some small blocks.
With multiple filters with 3D \(\begin{align} (6 \times 6 \times 3) * (3 \times 3 \times 3) = (4 \times 4) \\ (6 \times 6 \times 3) * (3 \times 3 \times 3) = (4 \times 4) \\ \to (4 \times 4 \times 2) \end{align}\)
As you go deeper in a neural network, gradually trade down whereas the number of channel will generally increase.
Pooling layer
The meaning of pooling is sampling the features. It will reduce the size of dimension of sample.
Because It has no parameters to learn, The hyperparameters in max pooling don’t affect to gradient descent
Normally not use padding for pooling.
Hyperparameters
-
$f$ : filter size
-
$s$: strides
Accepted volume size is $W_n, H_n, C_n$.
When output is updated after fooling
- $W_{n+1} = \lfloor \frac{W_n -f}{s} + 1 \rfloor$
- $H_{n+1} = \lfloor \frac{H_n -f}{s} + 1 \rfloor $
- $C_{n+1} = C_n$
max pooling
Get the max value in the filter and stride iteratively.
- filter size: $2 \times 2$
- stride: 2
average pooling
Get the average value in the filter and stride iteratively.
- filter size: $2 \times 2$
- stride: 2
Fully connected Layer
Fully connected layer is normal neural network. But, matrix input is not accepted. So feature map must be flatten for full connected layer.
\[\begin{bmatrix} 9 & 2 \\ 6 & 3 \end{bmatrix} \rightarrow \begin{bmatrix} 9 \\ 2 \\ 6 \\ 3 \end{bmatrix}\]The flow of CNN
If striding is meant to look over an image, pooling is the catching the meaningful point of image.
\[\text{Conv} \rightarrow \text{Pool} \rightarrow \text{Conv} \rightarrow \text{Pool} \rightarrow \text{Fully connected} \rightarrow \text{Soft max}\]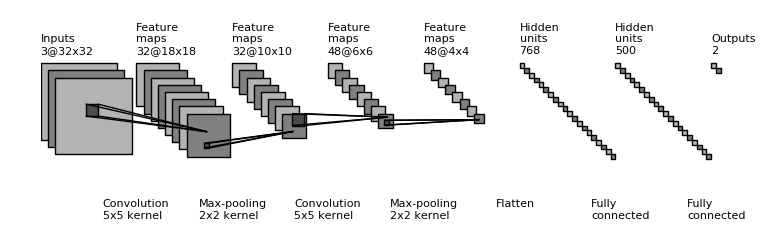
CNN implementation for MNIST
'''
A Convolutional Network implementation example using TensorFlow library.
This example is using the MNIST database of handwritten digits
(http://yann.lecun.com/exdb/mnist/)
Author: Aymeric Damien
Project: https://github.com/aymericdamien/TensorFlow-Examples/
'''
from __future__ import print_function
import tensorflow as tf
import time
# Import MNIST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
# Parameters
learning_rate = 0.001
training_iters = 100000
batch_size = 64
display_step = 10
# Network Parameters
n_input = 784 # MNIST data input (img shape: 28*28)
n_classes = 10 # MNIST total classes (0-9 digits)
dropout = 0.75 # Dropout, probability to keep units
# tf Graph input
x = tf.placeholder(tf.float32, [None, n_input])
y = tf.placeholder(tf.float32, [None, n_classes])
keep_prob = tf.placeholder(tf.float32) #dropout (keep probability)
# Create some wrappers for simplicity
def conv2d(x, W, b, strides=1):
# Conv2D wrapper, with bias and relu activation
x = tf.nn.conv2d(x, W, strides=[1, strides, strides, 1], padding='SAME')
x = tf.nn.bias_add(x, b)
return tf.nn.relu(x)
def maxpool2d(x, k=2):
# MaxPool2D wrapper
return tf.nn.max_pool(x, ksize=[1, k, k, 1], strides=[1, k, k, 1],
padding='SAME')
# Create model
def conv_net(x, weights, biases, dropout):
# Reshape input picture
x = tf.reshape(x, shape=[-1, 28, 28, 1])
# Convolution Layer
conv1 = conv2d(x, weights['wc1'], biases['bc1'])
# Max Pooling (down-sampling)
conv1 = maxpool2d(conv1, k=2)
# Convolution Layer
conv2 = conv2d(conv1, weights['wc2'], biases['bc2'])
# Max Pooling (down-sampling)
conv2 = maxpool2d(conv2, k=2)
# Fully connected layer
# Reshape conv2 output to fit fully connected layer input
fc1 = tf.reshape(conv2, [-1, weights['wd1'].get_shape().as_list()[0]])
fc1 = tf.add(tf.matmul(fc1, weights['wd1']), biases['bd1'])
fc1 = tf.nn.relu(fc1)
# Apply Dropout
fc1 = tf.nn.dropout(fc1, dropout)
# Output, class prediction
out = tf.add(tf.matmul(fc1, weights['out']), biases['out'])
return out
#Tensorflow GRAPH
# Store layers weight & bias
weights = {
# 5x5 conv, 1 input, 32 outputs
'wc1': tf.Variable(tf.random_normal([5, 5, 1, 32])),
# 5x5 conv, 32 inputs, 64 outputs
'wc2': tf.Variable(tf.random_normal([5, 5, 32, 64])),
# fully connected, 7*7*64 inputs, 1024 outputs
'wd1': tf.Variable(tf.random_normal([7*7*64, 1024])),
# 1024 inputs, 10 outputs (class prediction)
'out': tf.Variable(tf.random_normal([1024, n_classes]))
}
biases = {
'bc1': tf.Variable(tf.random_normal([32])),
'bc2': tf.Variable(tf.random_normal([64])),
'bd1': tf.Variable(tf.random_normal([1024])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
with tf.device('/gpu:0'):
# Construct model
pred = conv_net(x, weights, biases, keep_prob)
# Define loss and optimizer
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
# Evaluate model
correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Initializing the variables
init = tf.global_variables_initializer()
# Time checking
check_time = time.time()
# Launch the graph
with tf.Session(config=tf.ConfigProto(log_device_placement=True)) as sess:
sess.run(init)
step = 1
# Keep training until reach max iterations
while step * batch_size < training_iters:
batch_x, batch_y = mnist.train.next_batch(batch_size)
# Run optimization op (backprop)
sess.run(optimizer, feed_dict={x: batch_x, y: batch_y,
keep_prob: dropout})
if step % display_step == 0:
# Calculate batch loss and accuracy
loss, acc = sess.run([cost, accuracy], feed_dict={x: batch_x,
y: batch_y,
keep_prob: 1.})
print("Iter " + str(step*batch_size) + ", Minibatch Loss= " + \
"{:.6f}".format(loss) + ", Training Accuracy= " + \
"{:.5f}".format(acc))
step += 1
print("Optimization Finished!")
# Calculate accuracy for 256 mnist test images
print("Testing Accuracy:", \
sess.run(accuracy, feed_dict={x: mnist.test.images[:256],\
y: mnist.test.labels[:256],\
keep_prob: 1.}))
# GPU: 8.132946491241455
# CPU: 156.68687391281128
print(time.time() - check_time)